
著录项
申请号CN202011298517.5
公开号CN112434848A
申请(专利权)人西安理工大学
主分类号G06Q10/04
地址710048 陕西省西安市碑林区金花南路5号
代理机构西安弘理专利事务所
申请日2020-11-19
公开日2021-03-02
发明人段建东; 侯泽权; 王鹏; 马文涛; 方帅; 安琳
分类号G06Q10/04; G06Q50/04; G06N3/04; G06N3/08; G06K9/62
国省代码CN61
代理人王敏强
摘要
本发明公开了一种基于深度信念网络的非线性加权组合风电功率预测方法,属于电力系统风电功率预测技术领域。为了解决当下风电功率预测精度较低的问题,利用分解策略、非线性加权组合以及深度学习模型建立一种新的组合预测模型。首先采用结合重建误差率的变分模态分解VMD技术对原始风电功率序列进行分解,提取局部特征;然后,利用长短期记忆神经网络和基于粒子群优化的深度信念网络构建子预测模型。最后,采用基于粒子群优化的深度信念网络PSO‑DBN的非线性加权组合方法对多个子预测模型进行组合,建立短期风电功率预测的组合模型,进一步提高了风电功率预测的准确性和稳定性。
权利要求书
1.基于深度信念网络的非线性加权组合风电功率预测方法,其特征在于,包括以下步骤:步骤1、数据收集:收集风力发电的风速、历史风电功率、温度和风向数据并构建训练样本集;步骤2、数据预处理:首先,对风力发电数据中的异常数据进行修正,并对缺失数据进行补充;然后,对数据进行标准化处理以减小因数据数量级相差较大而对预测准确性造成的影响;最后,使用具有降噪功能的变分模态分解技术VMD分解非线性非平稳的历史风电功率序列,得到IMF1模态,IMF2,IMF3...IMFN模态,以提高数据的可预测性;步骤3、特征选择:计算各影响因素与历史风电功率的最大信息系数MIC,选取MIC>0.5的历史风电功率、风速、温度和风向作为主导影响因素参与步骤4中子模型的训练预测;步骤4、搭建子预测模型:将IMF1模态作为目标输出,将步骤3的风力发电的风速、历史风电功率、温度和风向数据作为输入,利用擅长处理时间序列问题的递归神经网络LSTM进行训练得到子预测模型1和子预测结果1;然后将IMF2模态作为目标输出,将步骤3的风力发电的风速、历史风电功率、温度和风向数据作为输入,利用擅长特征提取的深度信念模型DBN并结合粒子群优化PSO进行训练得到子预测模型2和子预测结果2,然后按照上述训练步骤依次循环直至IMFN结束,得到N个子预测模型及N个子预测结果;其中,IMF2,IMF3...IMFN都采用PSO-DBN模型进行预测训练。步骤5、模型组合:利用基于PSO-DBN的非线性组合机制对步骤4训练得到的N个子模型的N个预测结果进行组合,以更好地提取和表征各个子预测模型的非线性关系,从而得到非线性组合预测模型;步骤6、输出结果:输入预测日前两天的风力发电的风速、功率、温度和风向数据信息,根据组合预测模型得到最终的预测结果。
2.根据权利要求1所述的基于深度信念网络的非线性加权组合风电功率预测方法,其特征在于,步骤2所述数据预处理的方法为:首先,对风力发电数据中的异常数据进行修正,并对缺失数据进行补充;如果某个时刻的数据与前后两天对应时刻数据的差异过大,就认为该数据是极大或极小的数据,该类数据的修正规则如下:其中,X(d,t)是第d天t时刻的用电量数据,是第d天t时刻前后两天的用电量数据平均值,εd(t)是第d天用电量数据标准差的两倍,是第d天t时刻前后两天同时刻数据的平均值。对于缺失的数据按照公式(2)进行补充;然后按照标准化公式(3)对所有数据进行标准化处理:其中,xij为第i组第j个数据的真实值,为第i组第j个数据的归一化值,xmax为该组数据中的最大值,xmin为该组数据中的最小值;当然预测模型的输出结果还需要进行反归一化才可以得到最终结果,反归一化的规则如公式(4)所示:其中,yi为最终预测结果,为预测模型输出的归一化数据,ymax为该组数据的最大值,ymin为该组数据的最小值;最后,使用具有降噪功能的变分模态分解技术VMD去分解非线性非平稳的风电功率序列,以提高数据的可预测性。
3.根据权利要求1所述的基于深度信念网络的非线性加权组合风电功率预测方法,其特征在于,步骤2所述变分模态分解技术VMD是一种自适应的信号处理方法,通过迭代寻优,不断地更新各个子模态函数以及它们的中心频率,最终实现将实值信号f分解为N个模态函数IMF的功能;提出结合重构误差R来确定参数N,选取R<0.01时的N值作为最终参数,如式(9)所示:
4.据权利要求1所述的基于深度信念网络的非线性加权组合风电功率预测方法,其特征在于,步骤3最大信息系数MIC的具体计算公式如下:其中,p(X,Y)代表变量X和Y之间的联合概率,本发明中变量X代表历史功率,风速,温度和风向影响因素数据,变量Y代表风电功率数据。
5.据权利要求1所述的基于深度信念网络的非线性加权组合风电功率预测方法,其特征在于,步骤4所述递归神经网络LSTM通过输入门、遗忘门、输出门对具有长期存储器的单元状态进行控制,LSTM网络模型用式(11)表示:其中ft,it,ot分别是遗忘门,输入门和输出门,ht是t时刻的隐层输出值,C′t和Ct分别是t时刻单元状态需要更新的信息和t时刻单元状态的全部信息,Wxf,Whf,Wix,Wih,Wcx,Wch,Wox,Woh是两两之间的权重系数,bf,bi,bc,bo是修正系数。
说明书
技术领域
本发明属于电力系统风电功率预测技术领域,涉及一种基于深度信念网络的非线性加权组合风电功率预测方法。
背景技术
随着能源革命的发展,风能以其清洁、丰富、可再生的优势,成为世界上最具潜力的替代能源之一。但是,风能具有随机性、波动性和间歇性等固有特性,使风电功率序列呈现高度非线性和非平稳性,这会导致电力系统的电压和频率产生波动。而高精度的风电功率预测方法可以确保电力系统的安全稳定,提高电网运行效率并且可以增强风电在电力市场的竞争力。因此,准确的风电功率预测成为解决以上问题的有效手段。
当下机器学习是最为流行的预测模型,然而,反向传播(BP)神经网络、支持向量机(SVM)、Elman神经网络、极限学习机(extreme learning machine,ELM)等浅层学习模型具有陷入局部最优、过拟合、收敛性差等缺点。因此,深度学习模型凭借其无监督特征学习、较强的泛化能力和大数据训练三大属性,成为风速/功率预测的主流模型。但是单一的预测模型仍然无法满足当下电网对风电功率预测的精度要求。于是为了提高预测精度提出了组合预测模型。但是常用的线性组合使用线性函数进行各个子模型的组合虽然对预测精度有所提高但是线性的组合系数没有办法完全表征各个子模型的特性,预测精度随时间会降低,因此有必要研究一种高精度的风电功率非线性组合预测方法。
发明内容
本发明提供了一种基于深度信念网络的非线性加权组合风电功率预测方法,解决了现有风电功率预测精度较低的问题,克服了线性加权组合的不足,可以根据不断的学习训练随时调整各个子模型的权重系数,使得预测精度可以一直维持在很高的水平,可以有效提升风电功率预测精度,从而为电力系统的安全稳定运行提供参考。
本发明所采用的技术方案是,基于深度信念网络的非线性加权组合风电功率预测方法,包括以下步骤:
步骤1、数据收集:收集风力发电的风速、历史风电功率、温度和风向数据并构建训练样本集;
步骤2、数据预处理:首先,对风力发电数据中的异常数据进行修正,并对缺失数据进行补充;然后,对数据进行标准化处理以减小因数据数量级相差较大而对预测准确性造成的影响;最后,使用具有降噪功能的变分模态分解技术VMD分解非线性非平稳的历史风电功率序列,得到IMF1模态,IMF2,IMF3…IMFN模态,以提高数据的可预测性;
步骤3、特征选择:计算各影响因素与历史风电功率的最大信息系数MIC,选取MIC>0.5的历史风电功率、风速、温度和风向作为主导影响因素参与步骤4中子模型的训练预测;
步骤4、搭建子预测模型:将IMF1模态作为目标输出,将步骤3的风力发电的风速、历史风电功率、温度和风向数据作为输入,利用擅长处理时间序列问题的递归神经网络LSTM进行训练得到子预测模型1和子预测结果1;然后将IMF2模态作为目标输出,将步骤3的风力发电的风速、历史风电功率、温度和风向数据作为输入,利用擅长特征提取的深度信念模型DBN并结合粒子群优化PSO进行训练得到子预测模型2和子预测结果2,然后按照上述训练步骤依次循环直至IMFN结束,得到N个子预测模型及N个子预测结果;
其中,IMF2,IMF3…IMFN都采用PSO-DBN模型进行预测训练。
步骤5、模型组合:利用基于PSO-DBN的非线性组合机制对步骤4训练得到的N个子模型的N个预测结果进行组合,以更好地提取和表征各个子预测模型的非线性关系,从而得到非线性组合预测模型;
步骤6、输出结果:输入预测日前2天的风力发电的风速、功率、温度和风向数据信息,根据组合预测模型得到预测结果。
本发明的特点还在于,
步骤2数据预处理的方法为:
首先,对风力发电数据中的异常数据进行修正,并对缺失数据进行补充;
如果某个时刻的数据与前后两天对应时刻数据的差异过大,就认为该数据是极大或极小的数据,该类数据的修正规则如下:
其中,X(d,t)是第d天t时刻的用电量数据,是第d天t时刻前后两天的用电量数据平均值,εd(t)是第d天用电量数据标准差的两倍,是第d天t时刻前后两天同时刻数据的平均值。
对于缺失的数据按照公式(2)进行补充;
然后按照标准化公式(3)对所有数据进行标准化处理:
其中,xij为第i组第j个数据的真实值,为第i组第j个数据的归一化值,xmax为该组数据中的最大值,xmin为该组数据中的最小值;
当然预测模型的输出结果还需要进行反归一化才可以得到最终结果,反归一化的规则如公式(4)所示:
其中,yi为最终预测结果,为预测模型输出的归一化数据,ymax为该组数据的最大值,ymin为该组数据的最小值;
最后,使用具有降噪功能的变分模态分解技术VMD去分解非线性非平稳的风电功率序列,以提高数据的可预测性。
步骤2的变分模态分解技术VMD是一种自适应的信号处理方法,通过迭代寻优,不断地更新各个子模态函数以及它们的中心频率,最终实现将实值信号f分解为N个模态函数IMF的功能;
提出结合重构误差R来确定参数N,选取R<0.01时的N值作为最终参数,如式(9)所示:
步骤3最大信息系数MIC的具体计算公式如下:
其中,p(X,Y)代表变量X和Y之间的联合概率,本发明中变量X代表历史功率,风速,温度和风向影响因素数据,变量Y代表风电功率数据。
步骤4所述递归神经网络LSTM通过输入门、遗忘门、输出门对具有长期存储器的单元状态进行控制,LSTM网络模型用式(11)表示:
其中ft,it,ot分别是遗忘门,输入门和输出门,ht是t时刻的隐层输出值,C′t和Ct分别是t时刻单元状态需要更新的信息和t时刻单元状态的全部信息,Wxf,Whf,Wix,Wih,Wcx,Wch,Wox,Woh是两两之间的权重系数,bf,bi,bc,bo是修正系数。
本发明的有益效果是,使用VMD技术分解风电功率序列可以有效地提高可预测性,同时利用深度学习网络的LSTM模型和PSO-DBN模型增强预测性能,最后通过PSO-DBN进行非线性组合得到高精度的预测结果。与其他方法相比,本发明具有更高的预测精度和更强的预测性能,非常适合预测具有强非线性和高波动性的风电功率,可以有效提升风电功率预测精度,从而为电力系统的安全稳定运行提供参考。
附图说明
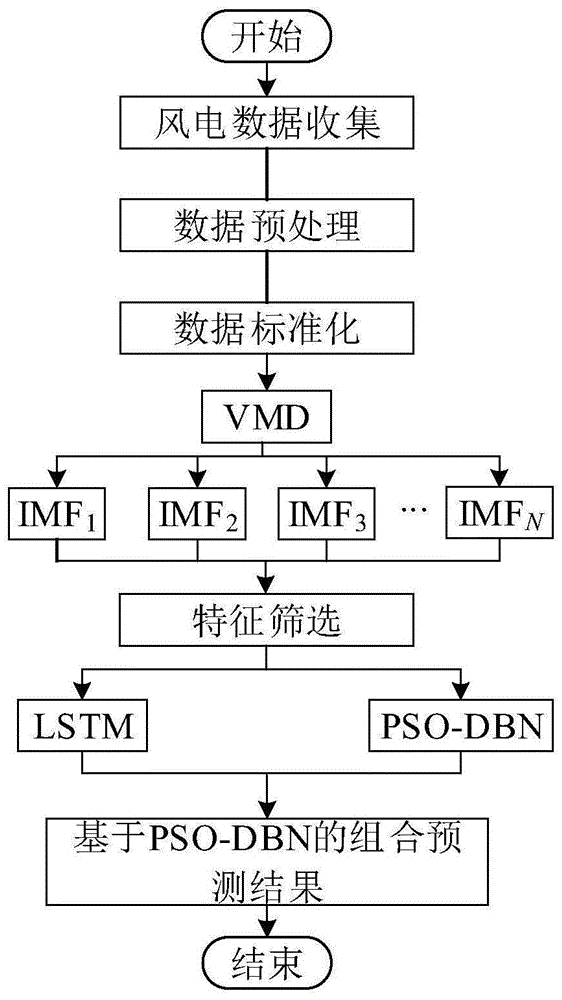
图1是本发明基于深度信念网络的非线性加权组合风电功率预测方法的流程示意图;
图2是本发明基于深度信念网络的非线性加权组合风电功率预测方法的非线性组合机制的结构图;
图3(a)是采用本发明基于深度信念网络的非线性加权组合风电功率预测方法与单一模型方法的预测风电功率比较图;
图3(b)是采用本发明基于深度信念网络的非线性加权组合风电功率预测方法与单一模型方法的误差比较图;
图4是采用本发明基于深度信念网络的非线性加权组合风电功率预测方法与传统线性叠加组合模型的预测风电功率比较图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明,但本发明并不限于这些方式。
基于深度信念网络的非线性加权组合风电功率预测方法的流程示意图如图1所示,包括以下步骤:
步骤1、数据收集,收集风力发电的风速、历史风电功率、温度和风向数据并构建训练样本集;
步骤2、数据预处理:首先,对风力发电数据中的异常数据进行修正,并对缺失数据进行补充;然后,对数据进行标准化处理以减小因数据数量级相差较大而对预测准确性造成的影响;最后,使用具有降噪功能的变分模态分解技术VMD分解非线性非平稳的历史风电功率序列,得到IMF1模态,IMF2,IMF3…IMFN模态,以提高数据的可预测性;
首先,对风力发电数据中的异常数据进行修正,并对缺失数据进行补充。
如果某个时刻的数据与前后两天对应时刻数据的差异过大,就认为该数据是极大或极小的数据,该类数据的修正规则如下:
其中,X(d,t)是第d天t时刻的用电量数据,是第d天t时刻前后两天的用电量数据平均值,εd(t)是第d天用电量数据标准差的两倍,是第d天t时刻前后两天同时刻数据的平均值。
对于缺失的数据按照公式(2)进行补充。
然后,对数据进行标准化处理以减小因数据数量级相差较大对预测准确性造成的影响。
按照标准化公式(3)对所有数据进行标准化处理:
其中xij为第i组第j个数据的真实值,为第i组第j个数据的归一化值,xmax为该组数据中的最大值,xmin为该组数据中的最小值。
当然预测模型的输出结果还需要进行反归一化才可以得到最终结果。反归一化的规则如公式(4)所示:
其中yi为最终预测结果,为预测模型输出的归一化数据,ymax为该组数据的最大值,ymin为该组数据的最小值。
最后,使用具有降噪功能的变分模态分解(VMD)技术去分解非线性非平稳的风电功率序列,以提高数据的可预测性。
VMD是一种自适应的信号处理方法,通过迭代寻优,不断地更新各个子模态函数以及它们的中心频率,最终实现将实值信号f分解为若干个模态函数(IMF)。VMD技术的关键在于如何对变分问题进行构造和求解。它首先将原始信号f(风电序列)构造成一个约束变分问题,如式(5)所示:
其中:uk为第N个模态函数(IMF),为时间t函数的偏导数,δ(t)为冲激函数,j为虚数单位,*为卷积运算。
为了便于求解,引入了二次罚因子α和拉格朗日乘数λ,将式(5)的约束变分问题转化为一个无约束变分问题,如式(6)所示:
然后利用ADMM技术求解非应变变分问题,如式(7)和式(8)所示:
最后,将原始输入信号(风电序列)分解为N个模态函数(IMF)。由于VMD技术分解的模态数N需要预先确定,因此为了保证VMD技术的分解性能,本发明提出重构误差率(R)指标来确定参数N,如式(9)所示:
步骤3、特征选择,计算各影响因素与历史风电功率的最大信息系数MIC,选取MIC>0.5的历史风电功率、风速、温度和风向作为主导影响因素参与步骤4中子模型的训练预测;
由于风电功率的各个影响因素数据呈现强非线性,为了更好的描述两个变量X和Y之间的关联程度,本发明采用MIC筛选出主导影响因素用于后续模型的训练与测试。MIC是一种适用于非线性数据关联度计算的方法,它比互信息(MI)具有更高的准确度,同时还具有低复杂度和高鲁棒性的特点,其计算公式如式(10)所示:
其中,p(X,Y)代表变量X和Y之间的联合概率,本发明中变量X代表历史功率,风速,温度和风向影响因素数据,变量Y代表风电功率数据。
步骤4、搭建子预测模型,将IMF1模态作为目标输出,将步骤3的风力发电的风速、历史风电功率、温度和风向数据作为输入,利用擅长处理时间序列问题的递归神经网络LSTM进行训练得到子预测模型1和子预测结果1;然后将IMF2模态作为目标输出,将步骤3的风力发电的风速、历史风电功率、温度和风向数据作为输入,利用擅长特征提取的深度信念模型DBN并结合粒子群优化PSO进行训练得到子预测模型2和子预测结果2,然后按照上述训练步骤依次循环直至IMFN结束,得到N个子预测模型及N个子预测结果;
其中,IMF2,IMF3…IMFN都采用PSO-DBN模型进行预测训练。
其中,LSTM网络是一种特殊的递归神经网络,它通过三个“门控结构”(输入门、遗忘门、输出门)对具有长期存储器的单元状态进行控制,有效地解决了经典RNN网络的梯度爆炸和梯度消失问题,同时也具备了学习长期时间信息序列的能力。因此选用LSTM网络进行预测代表了风电序列总体时间特性的IMF1。LSTM网络可以用式(11)表示。
其中ft,it,ot分别是遗忘门,输入门和输出门,ht是t时刻的隐层输出值,C′t和Ct分别是t时刻单元状态需要更新的信息和t时刻单元状态的全部信息,Wxf,Whf,Wix,Wih,Wcx,Wch,Wox,Woh是两两之间的权重系数,bf,bi,bc,bo是修正系数。
DBN网络(Deep-confidence network)是一个概率生成模型,它由一系列受限Boltzmann机器(RBM)和一个logistic回归层组成。RBM包含一个隐藏层,并在其中训练一个隐藏的数据层。DBN预测模型的底层采用无监督学习特性的贪婪算法逐层训练输入样本,即将第一层RBM结构训练得到的参数作为第二层RBM结构的输入,以此类推。该过程的目的是更有效地提取样本特征。DBN的顶层采用经典的BP神经网络结构回归预测。然后采用经典PSO算法确定每层神经元的数目,以提高DBN网络精度并降低复杂性。
最后得到LSTM网络和DBN模型的风电功率预测值。
步骤5、模型组合,利用基于PSO-DBN的非线性组合机制(如图2所示)对预测结果进行组合,以更好地提取和表征单个模型的非线性关系。
为了提高预测精度,提出了一种基于粒子群优化的深度信念网络的非线性加权组合预测模型。在得到各个独立子预测模型的预测结果后,通过基于PSO-DBN的非线性加权组合方法对这些预测结果进行非线性加权组合,建立短期风电功率的组合预测模型。
步骤6、输出结果,根据组合预测模型得到最终的预测结果,并选用MAE,RMSE和DM指标对预测结果进行评价。
为了定量分析预测性能,采用平均绝对误差MAE式,(12)和均方根误差RMSE,式(13)作为评价指标。
其中和表示和yi表示t时刻的预测值和实际值,N表示数据的总数。
此外,通过经典的Diebold-Mariano(DM)假设检验实验,进一步评价了所提出的组合模型的预测性能。其原理大致可以表述如下。首先,以两种预测模型的误差序列作为样本。在一定的显著性水平α上,原假设(H0)和备选假设(H1)如式(14)所示:
其中,L表示预测误差的损失函数,和表示两种不同模型的预测误差。
然后DM假设检验试验如式(15)所示
其中n表示预测值的长度,s2表示的方差估计值。
最后,通过比较|DM|和|Zα/2|的值判断是否拒绝原假设。即如果|DM|大于|Zα/2|,则表示两个模型的预测能力明显不同,反之亦然。
实施例
步骤1、收集风力发电的风速、历史功率、温度和风向等数据,考虑到数据采集的局限性,原始数据集采集时间间隔为10分钟,采集于陕西定边某风电场。使用7月份的2880个连续数据作为测试时间序列,其中前2304个数据作为训练数据集,最后576个数据作为单个模型的测试数据集。随后,将最后576个数据作为非线性组合研究的样本案例。同时,数据集的详细统计信息如表1所示,可以看到数据集具有很强的非线性和非平稳性。
表1风力发电数据集的特征
步骤2、首先,应用式(1)、式(2)对收集到的风力发电数据集中的异常数据进行筛选和修正。
然后,应用式(3)对风力发电的风速、历史功率、温度和风向等数据进行标准化处理以减小因数据数量级相差较大对预测准确性造成的影响。
最后,使用具有降噪功能的变分模态分解(VMD)技术去分解非线性非平稳的风电功率序列,以提高数据的可预测性。VMD技术的参数K由式(9)确定,当重构错误率小于0.01时确定最终参数K,其他参数取默认值。通过VMD分解后得到一系列的IMFs。
步骤3、应用式(10)计算最大信息系数(MIC),筛选出与风电功率关联程度最大的影响因素分别为:历史功率、风速、温度、风向。
步骤4、搭建子预测模型,利用擅长处理时间序列问题的LSTM模型来预测IMF1,利用擅长特征提取的DBN模型来预测剩余的IMF2,IMF3…IMFN。步骤3特征提取的风速、历史功率和温度作为LSTM模型的输入,IMF1作为输出。同样,将历史功率、风速、温度、风向作为PSO-DBN网络的输入。进行滚动预测即使用前三个预测值对第四个值进行预测。同时,组合预测模型中相关技术的参数设置如表2所示。
表2所提模型的主要参数
注意:LSTM和RBM的隐层神经元数量不是固定的,而是随IMF的特性而变化。
步骤5、模型组合,利用基于PSO-DBN的非线性组合机制对预测结果进行集成,以更好地提取和表征单个模型的非线性关系。
步骤6、根据组合预测模型得到最终的预测结果。为了考察组合模型的有效性,采用LSTM模型、PSO-DBN模型、Elman模型和BP模型作为比较模型,其预测结果如图3(a)-3(b)所示。此外,为了定量地比较各算法的性能,给出了不同算法的预测误差表3。从这个结果可以看出:1)与其他方法相比,本发明的预测精度更高,预测能力更强;2)单模型对具有不规则、强非线性特征的时间序列的预测存在一定的滞后。经分析主要原因是每个单一模型的结构有限,有一定的适用范围。
表3不同算法的预测误差
最后,本发明提出的非线性加权预测结果与常规线性叠加预测结果的对比如图4所示。结果表明:1)上述两种组合预测方法都能有效预测风电功率;2)从MAE和RMSE指标来看,本发明所提出的组合预测方法比经典线性叠加的预测精度更高。
附图
--
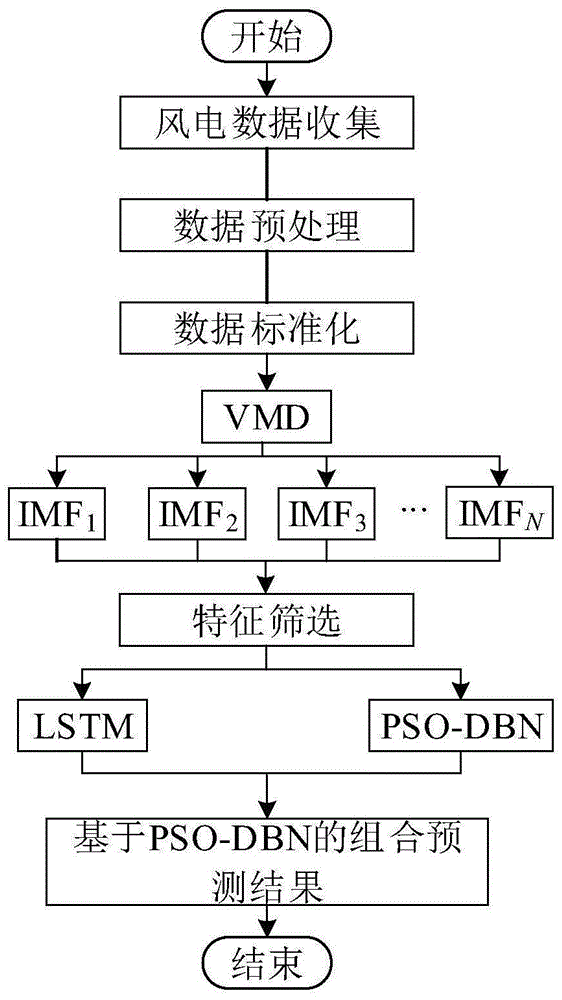
图1
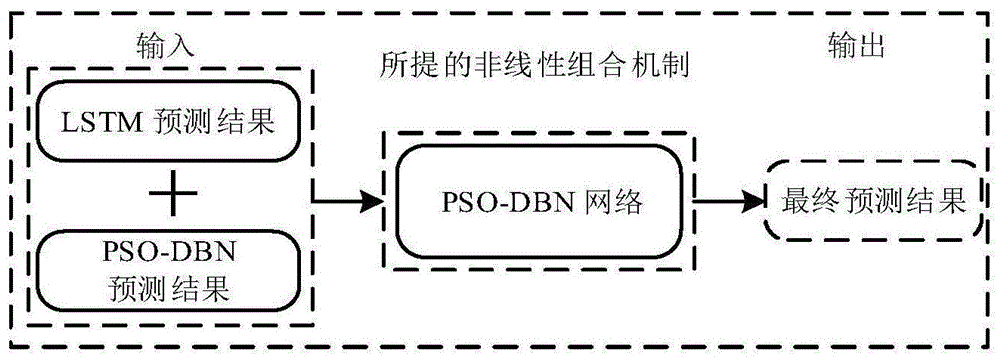
图2
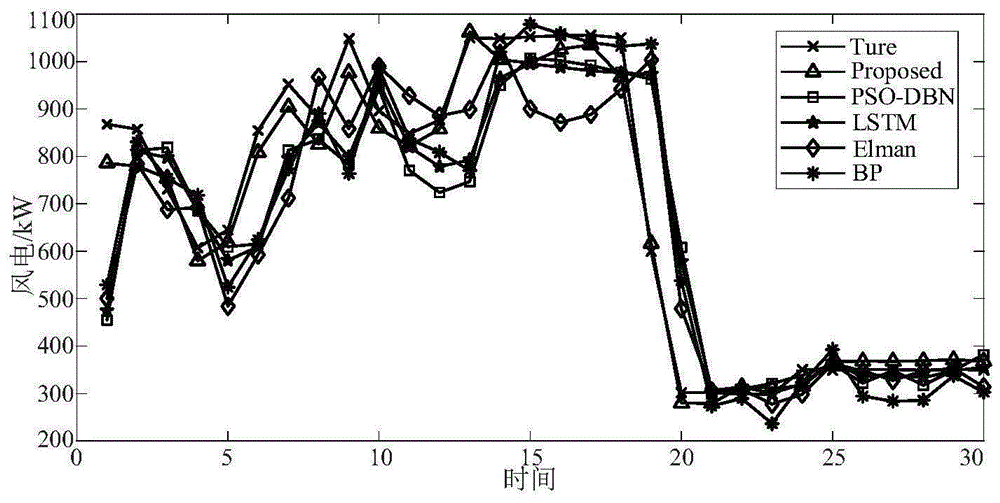
图3(a)
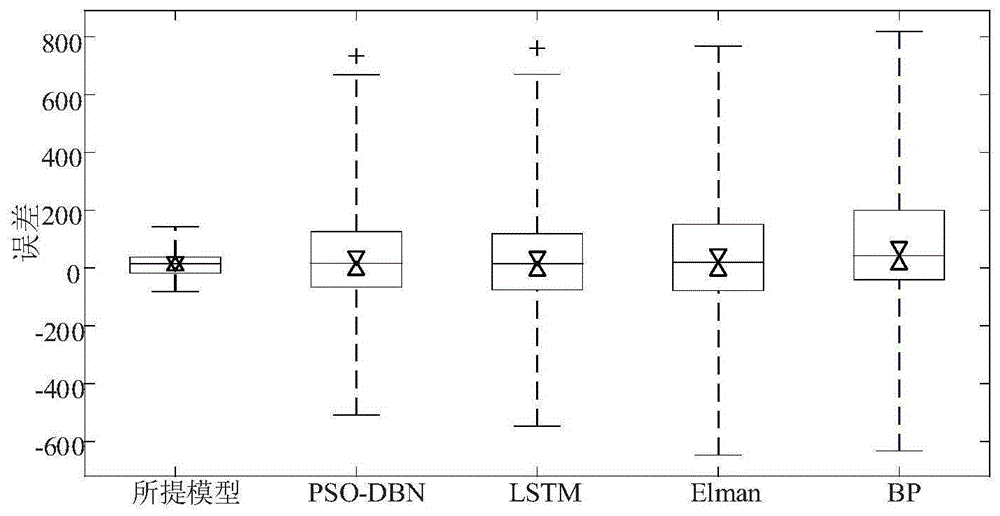
图3(b)
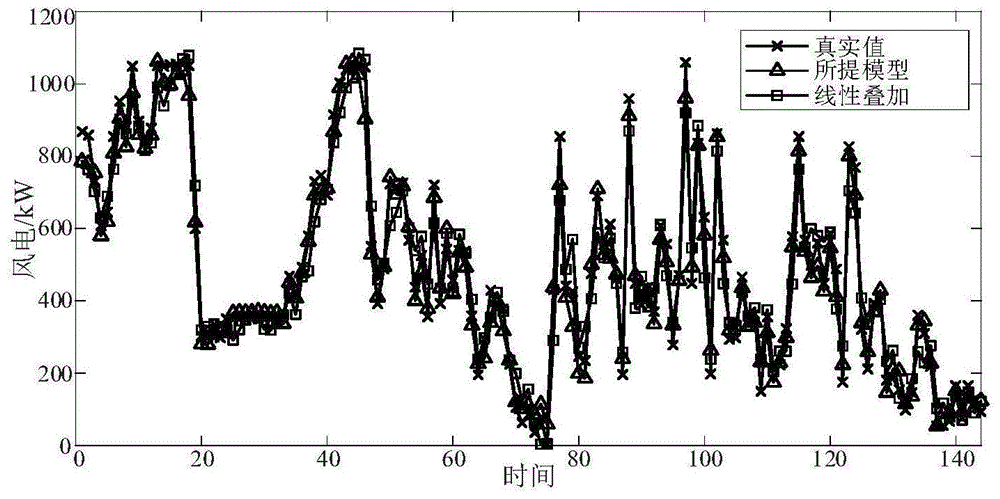
图4
评论
全部评论
共{{commentCount}}条{{rs.Msg_Content}}