
著录项
申请号CN202210433148.9
公开号CN114781264A
申请(专利权)人西安交通大学
主分类号G06F30/27
地址710049 陕西省西安市咸宁西路28号
代理机构北京中济纬天专利代理有限公司
申请日2022-04-22
公开日2022-07-22
发明人翟智; 王福金; 赵志斌; 郭艳婕; 文靖程; 陈雪峰
分类号G06F30/27; G06N3/04; G06N3/08; G06F119/02
国省代码CN61
代理人覃婧婵
摘要
基于特征解耦和趋势保持的锂电池跨域容量估计方法,包括:分别采集在不同工况下工作的锂电池充电过程中的过程量信号,包括:电压、电流和时间;将工况一下采集的数据作为源域数据,将工况二下采集的数据作为目标域数据;建立包括公有特征提取器、私有特征提取器、解码器、预测器和域分类器的域自适应网络;输入有标签的源域数据和无标签的目标域数据对该网络进行训练;训练完成后,将无标签的目标域数据输入训练好的域自适应网络进行前向传播,训练好的域自适应网络输出容量预测结果,实现不同工况下锂电池容量估计和健康状态评估。本公开能够有效提高估计精度、减小了域间差异以及保持了锂电池退化趋势信息从而提高了鲁棒性。
权利要求书
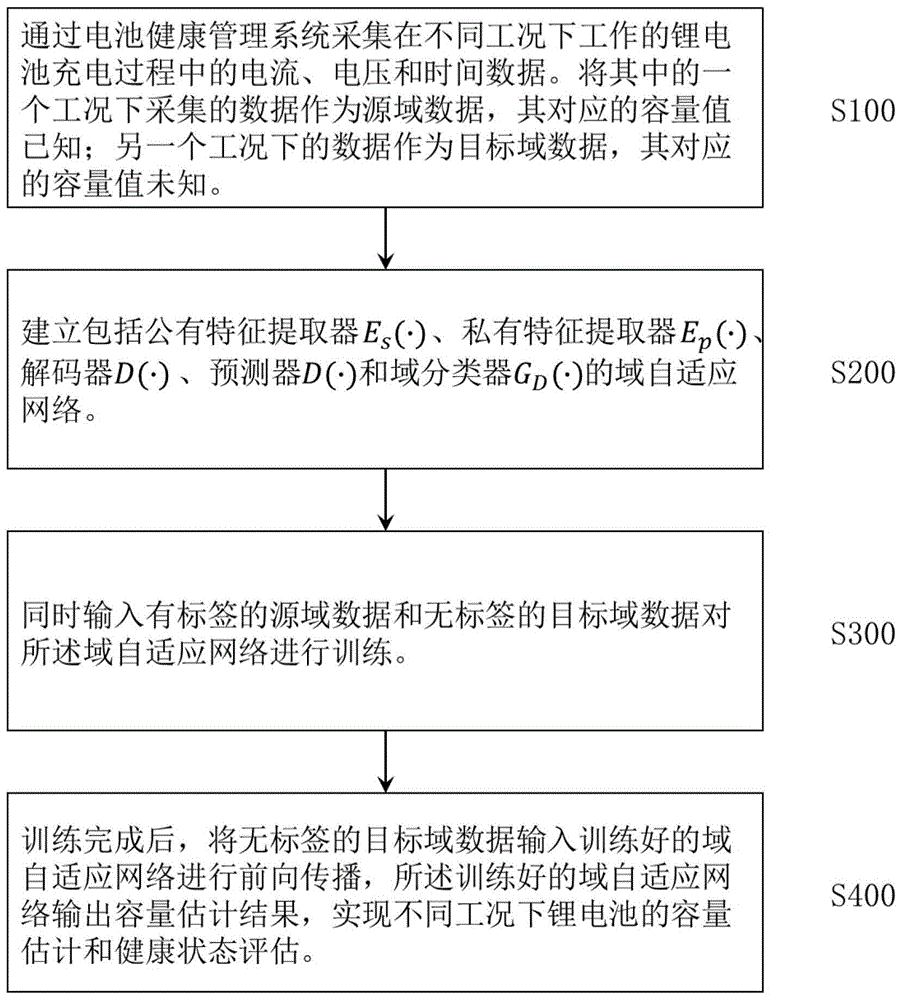
1.一种基于特征解耦和趋势保持的锂电池跨域容量估计方法,包括如下步骤:S100:通过电池健康管理系统采集在不同工况下工作的锂电池充电过程的过程量信号,将所述工况一下采集的过程量信号作为源域数据,其所对应的真实容量值是已知的,将所述工况二下采集的过程量信号作为目标域数据,其所对应的容量值是未知的;S200:建立包括公有特征提取器Es(·)、私有特征提取器Ep(·)、解码器D(·)、预测器P(·)和域分类器GD(·)的域自适应网络;S300:同时输入有标签的源域数据和无标签的目标域数据对所述域自适应网络进行训练;S400:训练完成后,将无标签的目标域数据输入训练好的域自适应网络进行前向传播,所述训练好的域自适应网络用于输出容量估计结果,实现不同工况下锂电池的容量估计和健康状态评估。
2.根据权利要求1所述的方法,其中,优选的,步骤S100中,所述过程量信号包括充电过程中记录的电流信号c、充电电压信号v和充电时间信号t,其对应的长度都为l,用x表示充电过程量数据,则:所述源域数据表示为:其中,表示第i个源域样本,表示与源域样本相对应当前充放电周期的容量值标签,Ns表示源域的样本数目。
3.根据权利要求1所述的方法,其中,步骤S100中,所述目标域数据表示为:其中,表示第i个目标域样本,Nt表示目标域的样本数目。
4.根据权利要求1所述的方法,其中,步骤S200中,所述公有特征提取器Es(·)、私有特征提取器Ep(·)有相同的结构,都由卷积层、池化层、批归一化层和全连接层构成,用于从输入数据中提取特征;所述解码器D(·)由反卷积层、批归一化层和全连接层组成,用于对提取的特征进行解码;所述预测器P(·)由全连接层构成,用于预测容量;所述域分类器GD(·)由全连接层构成,用于辨别输入的特征来自于源域还是目标域。
5.根据权利要求1所述的方法,其中,步骤S300中,对所述域自适应网络进行训练包括以下子步骤:S301:将有标签的源域数据和无标签的目标域数据同时输入公有特征提取器和私有特征提取器中进行前向传播,提取源域数据和目标域数据的特征,记为:其中:和分别表示从源域数据提取的公有特征和私有特征;和分别表示从目标域数据提取的公有特征和私有特征;S302:将所提取的公有特征和私有特征加和之后经过解码器进行前向传播,得到解码数据记为其中:zp+zs表示源域或目标域的公有特征与私有特征之和;S303:将所提取的源域数据的公有特征输入预测器进行前向传播,获得容量标签预测值,记为S304:将所提取的源域数据和目标域数据的公有特征经域分类器进行前向传播,获得域标签预测值,记为0或1;S305:根据所述容量预测值、域标签预测值、解码数据,计算得到预测器、域分类器、编码器和解码器的损失函数,再结合特征之间的区分性损失函数构造目标函数,目标函数构造完成后,进行反向传播;S306:重复执行步骤S301到步骤S304,当迭代次数达到设定的最大迭代次数时,域自适应网络训练完成。
6.根据权利要求5所述的方法,其中,步骤S301中,获得源域数据和目标域数据的公有特征和私有特征之后,并计算特征之间的区分性损失函数,表示为:其中:和表示分别由和分为行向量组成的矩阵,和表示分别由和分为行向量组成的矩阵,表示平方Frobenuis范数。
7.根据权利要求5所述的方法,其中,步骤S302中,获得解码数据后,根据真实数据,可计算获得编码器和解码器之间的损失,表示为:其中,表示期望,xi表示第i个样本,表示xi相对应的解码数据,表示一个批次的数据,表示相似度函数,表示为
8.根据权利要求5所述的方法,其中,步骤S303中,获得源域数据的容量预测值后,根据源域数据的真实容量标签,计算获得预测器的损失,预测器的损失表示为:
9.根据权利要求5所述的方法,其中,步骤S304中,获得域标签预测值后,根据真实的域标签,计算得到域分类器的损失,域分类器的损失表示为:其中,表示期望,表示所有源域样本,表示所有目标域样本;为第i个源域样本的域标签预测值,为第j个目标域样本的域标签预测值。
10.根据权利要求5所述的方法,其中,步骤S305中,所述损失函数表示为:L=Lpred+αLInfoNCE+βLdiff+γLadv其中,α、β和γ表示权衡系数,权衡系数用网格搜索技术进行搜索,最终确定最优系数组合。
说明书
技术领域
本公开属于锂电池健康状态评估领域,尤其涉及一种基于特征解耦和趋势保持的锂电池跨域容量估计方法。
背景技术
近年来,由于能从海量数据中自动提取特征的能力,深度学习方法被广泛应用于电池健康管理系统。但由于不同电池的工作条件不一样,打破了深度学习的训练样本与测试样本服从独立同分布的假设,导致深度学习在应用于电池容量估计的精度大大下降。现有的深度域自适应方法只让两个域的特征分布对齐,没有考虑域特有特征。在不同域的电池退化数据中,除了包含有反映电池退化趋势的信息外,还包含不同电池之间的个体差异信息和工况差异信息。强制特征对齐并不能得到一种好的域不变表示,因此需要一种能考虑域特有信息的模型。
在背景技术部分中公开的上述信息仅仅用于增强对本发明背景的理解,因此可能包含不构成在本国中本领域普通技术人员公知的现有技术的信息。
发明内容
针对现有技术中的不足,本公开的目的在于提供一种基于特征解耦和趋势保持的锂电池跨域容量估计方法。本方法将特征解耦为域不变的公有特征和域特有的私有特征,使私有特征中包含不同域之间的差异信息,公有特征包含反映电池退化趋势的信息。为了使特征更具有表示性,使用解码器对特征解码,并最大化解码数据和原始数据之间的互信息。最终域不变的公有特征被用来预测容量值标签。
为实现上述目的,本公开提供以下技术方案:
一种基于特征解耦和趋势保持的锂电池跨域容量估计方法,包括如下步骤:
S100:通过电池健康管理系统采集在不同工况下工作的锂电池充电过程的过程量信号,将所述工况一下采集的过程量信号作为源域数据,其所对应的真实容量值是已知的,将所述工况二下采集的过程量信号作为目标域数据,其所对应的容量值是未知的;
S200:建立包括公有特征提取器Es(·)、私有特征提取器Ep(·)、解码器D(·)、预测器P(·)和域分类器GD(·)的域自适应网络;
S300:同时输入有标签的源域数据和无标签的目标域数据对所述域自适应网络进行训练;
S400:训练完成后,将无标签的目标域数据输入训练好的域自适应网络进行前向传播,所述训练好的域自适应网络用于输出容量估计结果,实现不同工况下锂电池的容量估计和健康状态评估。
优选的,
步骤S100中,所述过程量信号包括充电过程中记录的电流信号c、充电电压信号v和充电时间信号t,其对应的长度都为l,用x表示充电过程量数据,则:
所述源域数据表示为:
其中,表示第i个源域样本,表示与源域样本相对应当前充放电周期的容量值标签,Ns表示源域的样本数目。
优选的,
步骤S100中,所述目标域数据表示为:
其中,表示第i个目标域样本,Nt表示目标域的样本数目。
优选的,
步骤S200中,所述公有特征提取器Es(·)、私有特征提取器Ep(·)有相同的结构,都由卷积层、池化层、批归一化层和全连接层构成,用于从输入数据中提取特征;
所述解码器D(·)由反卷积层、批归一化层和全连接层组成,用于对提取的特征进行解码;
所述预测器P(·)由全连接层构成,用于预测容量;
所述域分类器GD(·)由全连接层构成,用于辨别输入的特征来自于源域还是目标域。
优选的,
步骤S300中,对所述域自适应网络进行训练包括以下子步骤:
S301:将有标签的源域数据和无标签的目标域数据同时输入公有特征提取器和私有特征提取器中进行前向传播,提取源域数据和目标域数据的特征,记为:
其中:和分别表示从源域数据提取的公有特征和私有特征;和分别表示从目标域数据提取的公有特征和私有特征;
S302:将所提取的公有特征和私有特征加和之后经过解码器进行前向传播,得到解码数据记为
其中:zp+zs表示源域或目标域的公有特征与私有特征之和;
S303:将所提取的源域数据的公有特征输入预测器进行前向传播,获得容量标签预测值,记为
S304:将所提取的源域数据和目标域数据的公有特征经域分类器进行前向传播,获得域标签预测值,记为0或1;
S305:根据所述容量预测值、域标签预测值、解码数据,计算得到预测器、域分类器、编码器和解码器的损失函数,再结合特征之间的区分性损失函数构造目标函数,目标函数构造完成后,进行反向传播;
S306:重复执行步骤S301到步骤S304,当迭代次数达到设定的最大迭代次数时,域自适应网络训练完成。
优选的,
步骤S301中,获得源域数据和目标域数据的公有特征和私有特征之后,并计算特征之间的区分性损失函数,表示为:
其中:和表示分别由和分为行向量组成的矩阵,和表示分别由和分为行向量组成的矩阵,表示平方Frobenuis范数。
优选的,
步骤S302中,获得解码数据后,根据真实数据,可计算获得编码器和解码器之间的损失,表示为:
其中,表示期望,xi表示第i个样本,表示xi相对应的解码数据,表示一个批次的数据,表示相似度函数,表示为
优选的,
步骤S303中,获得源域数据的容量预测值后,根据源域数据的真实容量标签,计算获得预测器的损失,预测器的损失表示为:
优选的,
步骤S304中,获得域标签预测值后,根据真实的域标签,计算得到域分类器的损失,域分类器的损失表示为:
其中,表示期望,表示所有源域样本,表示所有目标域样本;为第i个源域样本的域标签预测值,为第j个目标域样本的域标签预测值。
优选的,
步骤S305中,所述损失函数表示为:
L=Lpred+αLInfoNCE+βLdiff+γLadv
其中,α、β和γ表示权衡系数,权衡系数用网格搜索技术进行搜索,最终确定最优系数组合。
与现有技术相比,本公开带来的有益效果为:创新性的在锂电池跨域容量估计领域提出特征解耦的思想,同时考虑了不同域内锂电池退化过程中的公有特征和私有特征;使用对比学习的方法来约束模型,使提取的特征更具表示性;提高了模型在目标域上的预测精度,增强了模型的鲁棒性。
附图说明
图1是本公开一个实施例提供的基于特征解耦和趋势保持的锂电池跨域容量估计方法流程图;
图2是本公开一个实施例提供的基于特征解耦和趋势保持的锂电池跨域容量估计方法的模型框架示意图;
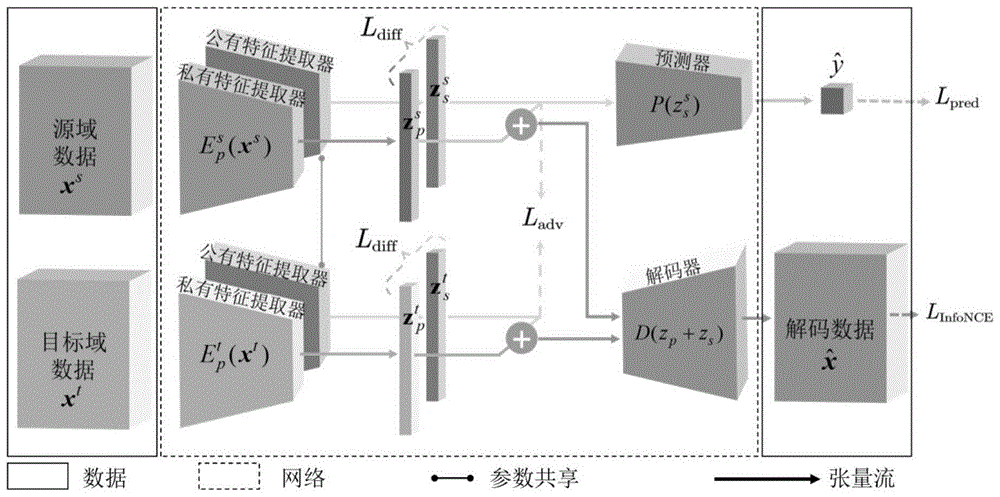
图3是本公开一个实施例提供的基于特征解耦和趋势保持的锂电池跨域容量估计方法的模型细节图。
具体实施方式
下面将参照附图1至图3详细地描述本公开的具体实施例。虽然附图中显示了本公开的具体实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
需要说明的是,在说明书及权利要求当中使用了某些词汇来指称特定组件。本领域技术人员应可以理解,技术人员可能会用不同名词来称呼同一个组件。本说明书及权利要求并不以名词的差异来作为区分组件的方式,而是以组件在功能上的差异来作为区分的准则。如在通篇说明书及权利要求当中所提及的“包含”或“包括”为一开放式用语,故应解释成“包含但不限定于”。说明书后续描述为实施本发明的较佳实施方式,然所述描述乃以说明书的一般原则为目的,并非用以限定本发明的范围。本公开的保护范围当视所附权利要求所界定者为准。
为便于对本公开实施例的理解,下面将结合附图以具体实施例为例做进一步的解释说明,且各个附图并不构成对本公开实施例的限定。
一个实施例中,如图1所示,本公开提供一种基于特征解耦和趋势保持的锂电池跨域容量估计方法,包括如下步骤:
S100:通过电池健康管理系统采集在不同工况下工作的锂电池充电过程的过程量信号,将所述工况一下采集的过程量信号作为源域数据,其所对应的真实容量值是已知的,将所述工况二下采集的过程量信号作为目标域数据,其所对应的容量值是未知的;
该步骤中,所述过程量信号包括充电电流信号c、充电电压信号v和充电时间信号t,其对应的长度都为l。用x表示充电过程量数据,则所述源域数据表示为:所述目标域数据表示为:
其中,表示第i个源域样本,表示与源域样本相对应的当前充放电周期的容量值标签,Ns表示源域的样本数目;表示第i个目标域样本,Nt表示目标域的样本数目。
能够理解,在采集信号过程中,不同域的电池的充电策略是不同的。
此外,对于本领域技术人员而言,源域和目标域是迁移学习中的两个基本概念,通常将已有的知识称为源域,需要学习的新知识称为目标域,通过迁移学习可以将源域的知识迁移到目标域上,具体到本实施例,源域数据可以是在某种充电策略下采集的、具有真实容量标签的数据,目标域则可以是在另一种工况下采集的、没有容量标签的数据。通过本实施例提供的方法,能够将源域数据中包含电池退化趋势信息迁移到目标域数据中,从而完成锂电池在另一种充放电策略下的容量估计。
S200:建立包括公有特征提取器Es(·)、私有特征提取器Ep(·)、解码器D(·)、预测器P(·)和域分类器GD(·)的域自适应网络;
该步骤中,所述公有特征提取器Es(·)、私有特征提取器Ep(·)有相同的结构,都由卷积层、池化层、批归一化层和全连接层构成,用于从输入数据中提取特征;所述解码器D(·)由反卷积层、批归一化层和全连接层组成,用于对提取的特征进行解码;所述预测器P(·)由全连接层构成,用于预测容量;所述的域分类器GD(·)由全连接层构成,用于辨别输入的特征来自于源域还是目标域。
S300:同时输入有标签的源域数据和无标签的目标域数据对所述域自适应网络进行训练;
S400:训练完成后,将无标签的目标域数据输入训练好的域自适应网络进行前向传播,所述训练好的域自适应网络用于输出容量估计结果,实现不同工况下锂电池的容量估计和健康状态评估。
本实施例通过将所采集的锂电池充电过程量信号的源域数据和目标域数据输入所构建的域自适应网络对该网络进行训练。首先将特征解耦为域特有的公有特征和域不变的私有特征,使私有特征中包含不同域之间的差异信息,公有特征包含反映电池退化趋势的信息。为使得特征更具有表示性,使用解码器对特征解码,并最大化解码数据和原始数据之间的互信息。最终域不变的公有特征被用来预测容量值标签。整个模型在考虑到域不变退化信息的同时忽略了域特有的其他干扰信息,因此模型的鲁棒性有很大提升。
另一个实施列中,步骤S300中,对所述域自适应网络进行训练包括以下步骤:
S301:将有标签的源域数据和无标签的目标域数据同时输入公有特征提取器和私有特征提取器中进行前向传播,提取源域数据和目标域数据的特征,记为:
其中:和分别表示从源域数据提取的公有特征和私有特征;和分别表示从目标域数据提取的公有特征和私有特征;
该步骤中,获得源域数据和目标域数据的公有特征和私有特征之后,可计算特征之间的区分性损失函数,表示为:
其中:和表示分别由和分为行向量组成的矩阵,和表示分别由和分为行向量组成的矩阵,表示平方Frobenuis范数;
S302:将所提取的公有特征和私有特征加和之后经过解码器进行前向传播,得到解码数据记为
其中:zp+zs表示源域或目标域的公有特征与私有特征之和;
该步骤中,获得解码数据后,根据真实数据,可计算获得编码器和解码器的损失,表示为:
其中,表示期望,xi表示第i个样本,表示xi相对应的解码数据,表示一个批次的数据,表示相似度函数,表示为
S303:将所提取的源域数据的公有特征输入预测器进行前向传播,获得容量标签预测值,记为
该步骤中,获得源域数据的容量预测值后,根据源域数据的真实容量标签,可计算获得预测器的损失,预测器的损失表示为:
S304:将所提取的源域数据和目标域数据的公有特征经域分类器进行前向传播,获得域标签预测值,记为0或1;
该步骤中,获得域标签预测值后,根据真实的域标签,可计算得到域分类器的损失,域分类器的损失表示为:
其中,表示期望,表示所有源域样本,表示所有目标域样本。为第i个源域样本的域标签预测值,为第j个目标域样本的域标签预测值。
S305:根据所述容量预测值、域标签预测值、解码数据,计算得到预测器、域分类器、编码器和解码器的损失函数,再结合特征之间的区分性损失函数构造目标函数,目标函数构造完成后,进行反向传播;
该步骤中,所述损失函数表示为:
L=Lpred+αLInfoNCE+βLdiff+γLadv
其中,α、β和γ表示权衡系数。可用网格搜索技术对权衡系数进行搜索,最终确定最优系数组合。
S306:重复执行步骤S301到步骤S304,当迭代次数达到设定的最大迭代次数时,域自适应网络训练完成。
针对上述训练步骤,结合前文所述,源域数据和目标域数据可以是在不同的充放电策略下采集获得,因此它们具有不同的统计分布,通过采用本实施例的训练方法,可以减小源域和目标域特征分布的差异,从而可以利用由源域数据训练获得的预测器对目标域数据进行高精度的容量估计。
图2是基于特征解耦和趋势保持的锂电池跨域容量估计方法的模型结构示意图。如图2所示,一方面,通过对公有特征提取器进行训练,其生成的特征令域分类器无法分辨该特征来自源域还是目标域;另一方面,对域分类器进行训练,使其尽可能能够分辨特征来自源域还是目标域。在这一对抗过程中,深度网络可以学习到域不变特征。另外,在公有特征提取器和私有特征提取器之间施加约束,使公有特征提取器和私有特征提取器提取的特征不相似,从而实现特征解耦的目的;在解码数据和原始数据之间添加约束,使特征提取器提取的特征更具有表示性。此外,通过最小化容量预测值的均方根误差损失,使得预测器能够正确预测样本的容量标签。
图3是提出的域自适应网络的详细架构图,是对图2的进一步详细展示。能够理解,图3中的特征提取器、解码器和预测器只是对网络模块功能的描述,可由卷积层、池化层、批归一化层和全连接层构成等组成,而非某一特定结构。技术人员可能会用不同名词来称呼同一个组件。本说明书及权利要求并不以名词的差异来作为区分组件的方式,而是以组件在功能上的差异来作为区分的准则。
下面,通过与无域自适应结构(NoAdaptation)、深度卷积神经网络(DCNN)、最大均值差异(MMD)和对抗域自适应(DANN)进行对比实验,进一步说明本公开的技术方案。
具体的,本次对比实验采用的主要评价指标是均方根误差和平均绝对误差。
实验使用的数据是锂电池在不同充放电策略下采集的数据,其中xi表示第i个充电周期中采集的电流、电压和时间数据,每个周期采集128个点,因此,yi为第i个充电周期对应的容量。充电策略如表格1所示。一共有4个域的数据,因此可以构成12个迁移任务。
表1
①3.6→6→5.6→4.755C表示以3.6C的电流从0充到20%,以6C的电流从20%充到40%,以5.6C的电流从40%充到60%,以4.755C从60%充到80%。每一种充电策略保证从0充到80%所用总时间为10分钟。最后以恒压恒流的模式从80%充到100%。
为确保实验的公平性,所有方法都用了相同的超参数设置,所有方法的预测精度如表2所示。
表2
上述的具体实施方案仅仅是示意性的、指导性的,而不是限制性的。本领域的普通技术人员在本说明书的启示下和在不脱离本公开权利要求所保护的范围的情况下,还可以做出很多种的形式,这些均属于本公开保护之列。
附图
--
图1
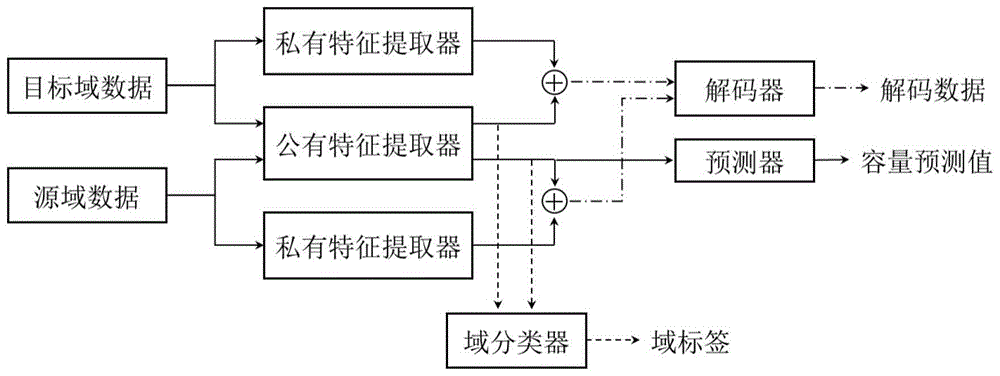
图2
评论
全部评论
共{{commentCount}}条{{rs.Msg_Content}}